|
I am a 2nd year PhD student of ECE department, Northwestern University advised by Qi Zhu, and I also work closely with Zhaoran Wang and Chao Huang. Before Northwestern, I did my undergrad on Applied Math and Computer Science at UC Berkeley, where I was advised by Sanjit A. Seshia. I had experience on Ubiquitous Computing and Novel sensing and have been fortunately advised by Teng Han and Tian Feng. I'm interested in combining techniques from machine learning, control theory, and formal method to enforce safety and robustness of various cyber-physics systems applications. I'm also broadly interested in Generative Models, Human Factor, and AI4Math (Theorem Proving in LEAN, Autoformalism, etc.). Email / CV / Google Scholar / DBLP / Github |

|
|
[05/2025] I will start my summer internship at Amazon as Applied Scientist in Palo Alto office. Happy to connect! [05/2025] Our paper "Directly Forecasting Belief for Reinforcement Learning with Delays" is accepted to ICML 2025 [10/2024] Our paper "Variatinoal Policy Delayed Optimization" is accepted to Neurips 2024(Spotlight!) [06/2024] Our paper "Kinematics-aware Trajectory Generation and Prediction with Latent SDE" is accepted to IROS 2024 [06/2024] Our paper "Case Study: Runtime Safety Verification of Neural Network Controlled System" is accepted to RV 2024 [06/2024] Our paper "Switching Controller Synthesis for Hybrid Systems Against STL Formulas" is accepted to FM 2024 [05/2024] Our paper "Boosting long delayed RL with auxiliary short delay" is accepted to ICML 2024 [05/2024] I will attend SSFT 2024. Please feel free to reach out if you are interested in my research [04/2024] Our paper "State-wise Safe RL With Pixel Observations" is accepted to L4DC 2024 [03/2024] One paper accepted to LLMAgent@ICLR 2024 [09/2023] I will start my PhD journey at ECE department, Northwestern University |
|
| |

|
Simon Sinong Zhan, Qingyuan Wu, Philip Wang, Yixuan Wang, Ruochen Jiao, Chao Huang, Qi Zhu, In Submission Our project introduces a model-based adversarial Inverse Reinforcement Learning framework that enhances performance in stochastic environments by incorporating transition dynamics into reward shaping, significantly improving sample efficiency and robustness compared to traditional approaches. |

|
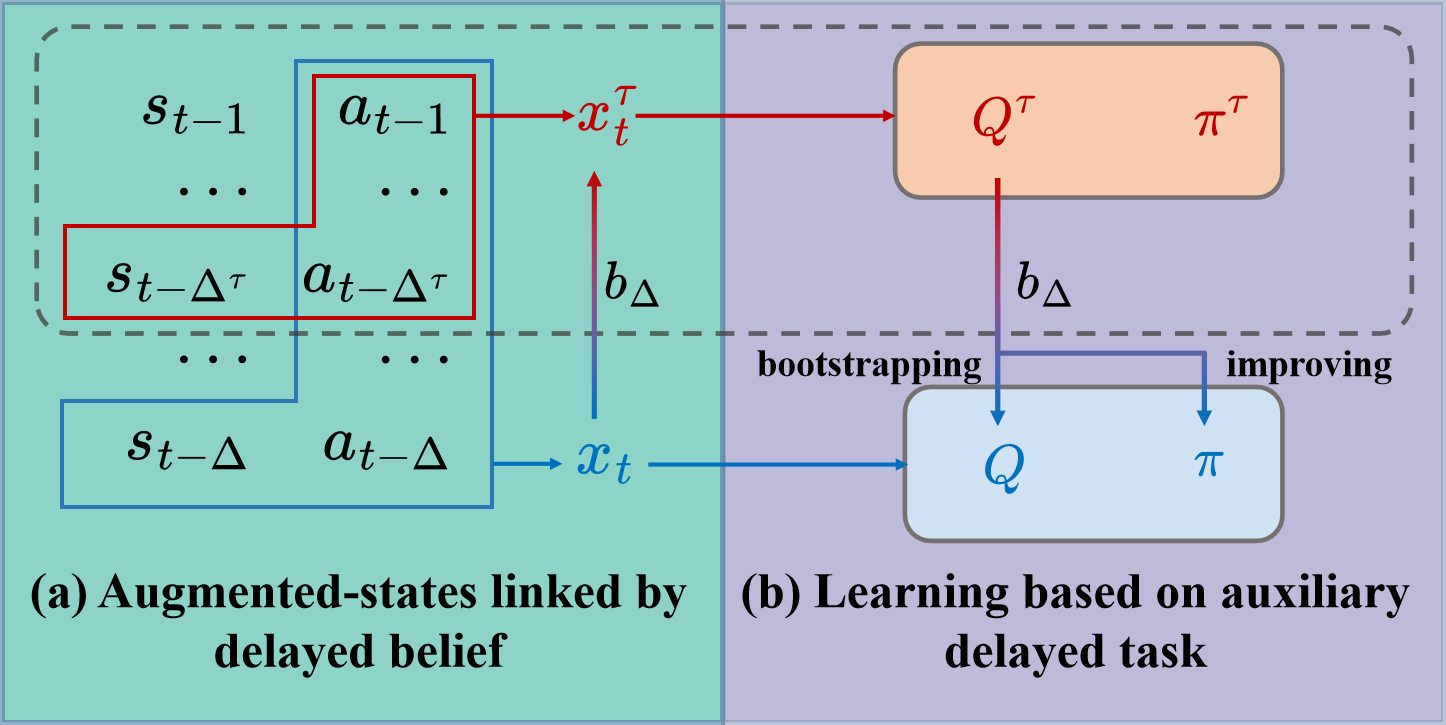
Qingyuan Wu*, Simon Sinong Zhan*, Yixuan Wang, Yuhui Wang, Chung-Wei Lin, Chen Lv, Qi Zhu, Chao Huang, Neurips 2024(Spotlight) arXiv Variational Delayed Policy Optimization (VDPO) reformulates delayed RL as a variational inference problem, which is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. |
|
Qingyuan Wu, Simon Sinong Zhan, Yixuan Wang, Yuhui Wang, Chung-Wei Lin, Chen Lv, Qi Zhu, Jürgen Schmidhuber, Chao Huang, ICML 2024 arXiv code Auxiliary-Delayed Reinforcement Learning (AD-RL) leverages an auxiliary short-delayed task to accelerate the learning on a long-delayed task without compromising the performance in stochastic environments. |

|
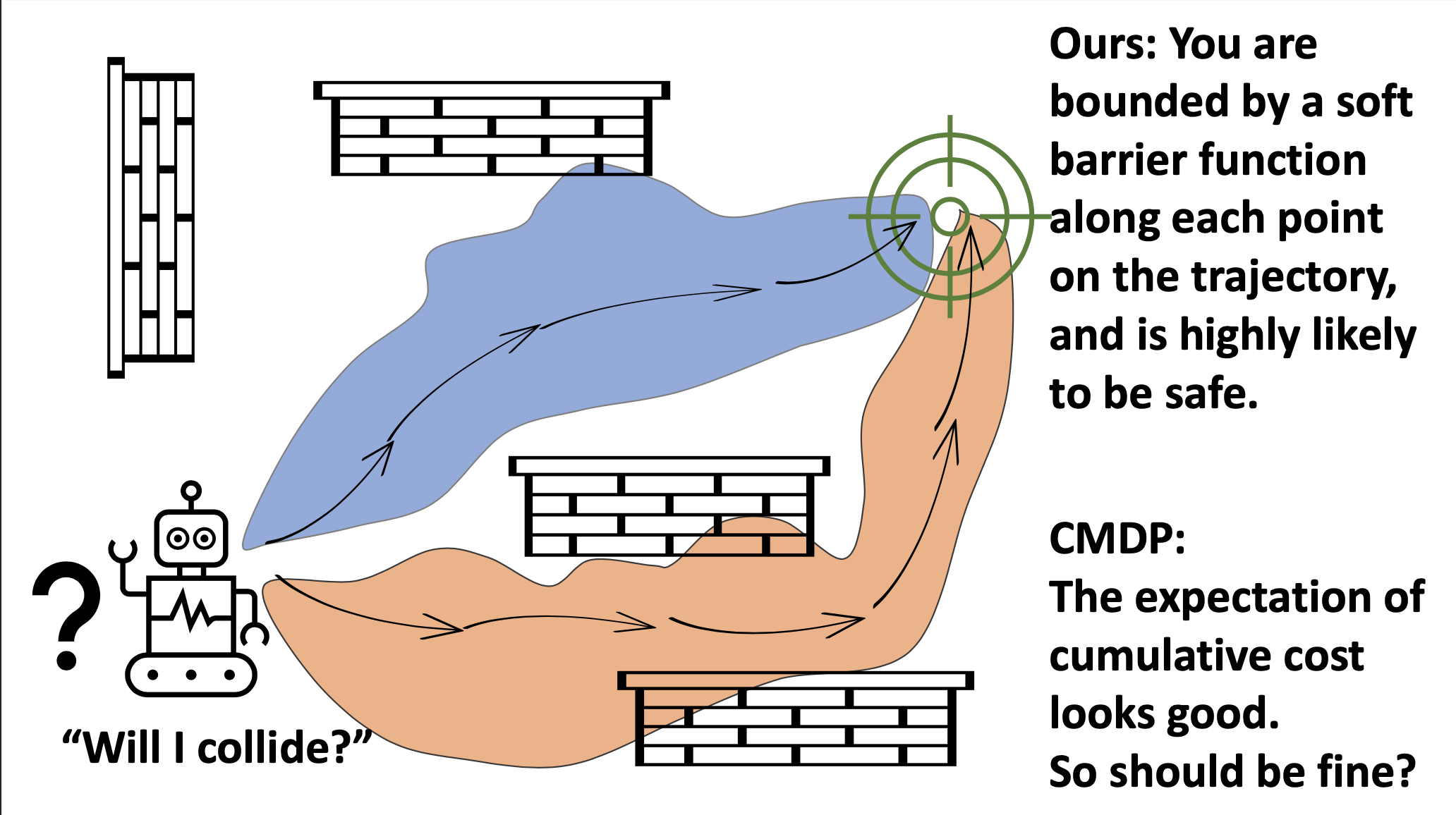
Simon Sinong Zhan, Yixuan Wang, Qingyuan Wu, Ruochen Jiao, Chao Huang, Qi Zhu, L4DC 2024 arXiv / code and demos In this paper, we propose a novel pixel-observation safe RL algorithm that efficiently encodes state-wise safety constraints with unknown hazard regions through the introduction of a latent barrier function learning mechanism. |
|
Yixuan Wang, Simon Sinong Zhan, Ruochen Jiao, Zhilu Wang, Wanxin Jin, Zhuoran Yang, Zhaoran Wang, Chao Huang, Qi Zhu, ICML 2023 arXiv / code A safe RL approach that can jointly learn the environment and optimize the control policy, while effectively avoiding unsafe regions with safety probability optimization. |
|
Yixuan Wang*, Simon Sinong Zhan*, Zhilu Wang, Chao Huang, Zhaoran Wang, Zhuoran Yang, Qi Zhu, ICCPS 2023 arXiv / code A framework that jointly conducts reinforcement learning and formal verification by formulating and solving a novel bilevel optimization problem, which is end-to-end differentiable by the gradients from the value function and certificates formulated by linear programs and semi-definite programs. |
|
MARS: a toolchain for Modeling, Analyzing and veRifying hybrid Systems |
|
|
|
|
|
|